前一章我們拆解了 Transformer Encoder 的結構,從多層的 Self-Attention 到 Feed Forward Network,看到它如何在編碼過程中同時捕捉序列中長短距依賴關係,並且將輸入轉換成上下文相關的語意表示。這樣的設計使得 Encoder 能夠提供一個固定不變的語境基底,而今天我們將要延續這些程式與邏輯繼續介紹Transformer Deocer
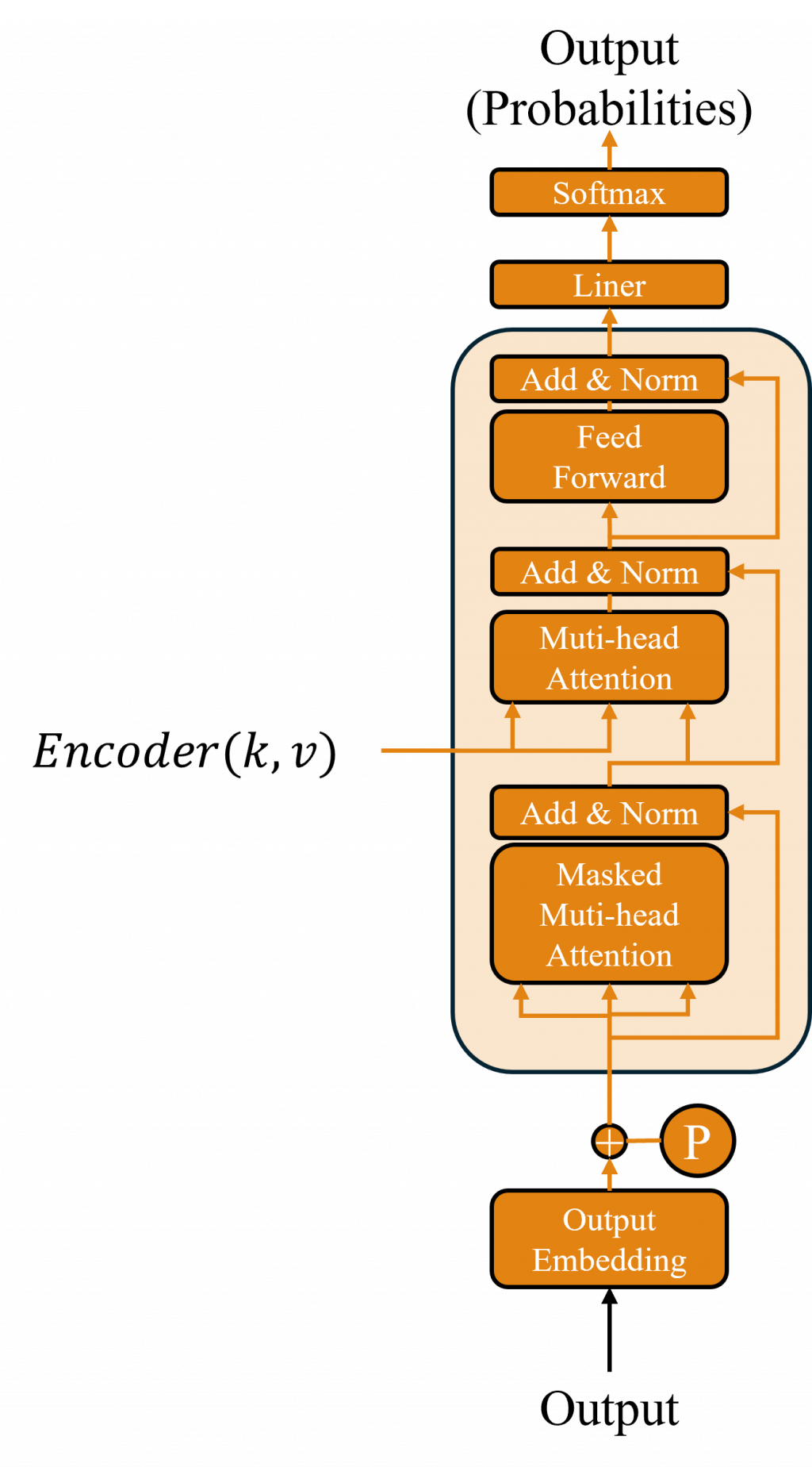
很多人第一次看到 Transformer 的 Decoder 都會冒出一個疑問:「欸?這東西不是並行運算嗎?那它怎麼確保模型不會偷看答案啊?」這個問題的答案就是Masked Multi-Head Attention。
想像你在考試寫作文,規定是一個字一個字往下寫,不能偷看老師在後面偷偷幫你寫好的段落。如果模型沒有限制,它在訓練時就能一次看完整句話,那生成就變成抄答案而不是預測下一步,這樣的話測試時效果肯定會出問題,因此我們做法很簡單,就是在注意力矩陣裡塞一個「下三角遮罩」,而我們可以分常兩個
import torch
def create_causal_mask(seq_len, device=None):
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
if device is not None:
mask = mask.to(device)
return mask
# 測試
mask = create_causal_mask(5)
print(mask.int())
輸出結果:
tensor([[0, 1, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 1, 1],
[0, 0, 0, 0, 1],
[0, 0, 0, 0, 0]], dtype=torch.int32)
很直覺吧?0 代表「可以看到」,1 代表「未來要遮起來」。
Decoder 裡每一層都有兩個注意力模組。第一個就是 Masked Multi-Head Attention,它的作用是讓模型「只能看到自己已經寫出來的東西」。簡單來說就是我們的Encoder模型的Attention作法只不過會多計算一個下三角遮罩罷了。
另一個模組是 Cross-Attention,這個比較有趣。它的功能是讓 Decoder 抬頭去看 Encoder 給的資訊。打個比方像你在做英文翻中文的翻譯,Decoder 在寫中文的時候,會不時抬頭瞄一眼原本的英文句子,確認現在該怎麼翻才比較貼切。
class DecoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ff = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.drop = nn.Dropout(dropout)
def forward(self, x, memory, tgt_mask: torch.Tensor | None, memory_mask: torch.Tensor | None):
x = self.norm1(x + self.drop(self.self_attn(x, x, x, tgt_mask)))
x = self.norm2(x + self.drop(self.cross_attn(x, memory, memory, memory_mask)))
x = self.norm3(x + self.drop(self.ff(x)))
return x
因此如果 Decoder 沒有 Cross-Attention,它就像是在自己講自己的話。雖然句子可能文法正確,聽起來也很順,但問題是它根本沒在參考原始輸入的內容。加上 Cross-Attention,就像搭了一座橋,讓 Decoder 在每一步生成時,都能回頭看看 Encoder 理解了什麼,這樣才有辦法寫出真正有對應關係的翻譯或回應。
但如果我們根本沒有 Encoder 模型,那當然也就不會用到 Cross-Attention。這也正是現在的語言模型模型產生幻覺(hallucination的最大原因之一。因為現在的語言模型大多是Decoder Only,當 Decoder 只用Self-Attention時,它在生成內容時就是一邊看自己剛剛寫過什麼、一邊繼續編。整個過程像是它在和自己對話。這樣雖然結果可能語句通順、邏輯也還行,可惜的是,它沒真的在看輸入內容,所以很容易就開始自己想像,寫出來的東西看似合理,其實跟原文沒啥關係這就是我們說的幻覺。
當然Cross-Attention 雖然能降低幻覺風險,但它不是萬靈丹,幻覺出現還可能是其他原因比如:
所以 Cross-Attention 的確像是一道安全鎖,但幻覺這件事的核心,還是出在模型自己講自己的話加上訓練過程中的偏差,要真的解決這個問題至今還是很困難的事情,因為這已經是模型的特性了。
而接下來讓我們看看標準的 Transformer 架構中,來清楚看到 Encoder 和 Decoder 的分工,而 memory(即 Encoder 最後一層的輸出)在 Decoder 的整個 forward 過程中保持不變。這其實是 Transformer 的一個經典設計Encoder 提供一個固定的語境表示,而 Decoder 則以此為基礎進行條件生成。
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, N, num_heads, d_ff, dropout=0.1, pad_idx=0):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model, padding_idx=pad_idx)
self.pos = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(N)])
self.drop = nn.Dropout(dropout)
self.pad_idx = pad_idx
self.d_model = d_model
def forward(self, tgt, memory, memory_key_mask):
# tgt: (B, Lt), memory: (B, Ls, d), memory_key_mask: (B,1,1,Ls) True=遮
B, Lt = tgt.shape
device = tgt.device
# 1) self-attn 的三種遮罩:causal(未來)、key padding(tgt中<pad>當K/V)、query padding(tgt中<pad>當Q)
causal = make_causal_mask(Lt, device) # (1,1,Lt,Lt)
kpad_t = make_key_pad_mask(tgt, self.pad_idx) # (B,1,1,Lt)
qpad_t = make_query_pad_mask(tgt, self.pad_idx) # (B,1,Lt,1)
self_mask = causal | kpad_t | qpad_t # (B,1,Lt,Lt)
# 2) cross-attn 遮罩:memory 的 key padding + 當前查詢若是 pad 也一併遮
cross_mask = memory_key_mask | qpad_t # (B,1,Lt,Ls)
x = self.embed(tgt) * math.sqrt(self.d_model)
x = self.drop(self.pos(x))
for layer in self.layers:
x = layer(x, memory, self_mask, cross_mask)
return x
class Transformer(nn.Module):
def __init__(self, src_vocab, tgt_vocab, d_model=512, N=6, num_heads=8, d_ff=2048, dropout=0.1, pad_idx=0):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, num_heads, d_ff, dropout, pad_idx)
self.decoder = Decoder(tgt_vocab, d_model, N, num_heads, d_ff, dropout, pad_idx)
self.generator = nn.Linear(d_model, tgt_vocab)
self.pad_idx = pad_idx
# 實務優化:輸出層與輸入嵌入權重綁定(可省參數、常帶來微幅提升)
self.generator.weight = self.decoder.embed.weight
def forward(self, src, tgt):
# encoder 回傳:memory, src_key_mask(B,1,1,Ls) True=遮
memory, src_key_mask = self.encoder(src)
dec_out = self.decoder(tgt, memory, src_key_mask) # (B,Lt,d)
logits = self.generator(dec_out) # (B,Lt,Vt)
return logits
然而這樣的設計也不是完全無懈可擊,這個固定不變的 memory 在一些應用場景中,特別是需要細緻地根據 Decoder 當前狀態調整語境的情況下,可能會成為一種限制。就像我們在討論 Seq2Seq 架構的時候提到的那樣,靜態的編碼表示有時候無法提供足夠的彈性來處理複雜輸出序列的生成。
不過前面那些 Encoder、Decoder 的內容可能有點久遠了,你大概也忘了 Attention、FFN、Skip connection 這些是怎麼做的。所以這邊我們就直接把完整的 Transformer Wx+b 程式碼貼給你參考。
# transformer.py
# Python 3.10+, PyTorch 2.x
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
# ---- Positional Encoding (sinusoidal) ----
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, max_len: int = 5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
pos = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(pos * div)
pe[:, 1::2] = torch.cos(pos * div)
self.register_buffer("pe", pe.unsqueeze(0)) # (1, max_len, d_model)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: (B, L, D)
return x + self.pe[:, :x.size(1)]
# ---- Masks ----
def make_subsequent_mask(L: int, device=None) -> torch.Tensor:
# (L, L), True=可見
m = torch.tril(torch.ones(L, L, dtype=torch.bool, device=device))
return m
def make_pad_mask(seq: torch.Tensor, pad_idx: int) -> torch.Tensor:
# seq: (B, L) -> (B, 1, 1, L), True=非PAD
return (seq != pad_idx).unsqueeze(1).unsqueeze(2)
# ---- Multi-Head Attention (純線性 Wx+b 投影) ----
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, dropout: float = 0.1):
super().__init__()
assert d_model % num_heads == 0
self.h = num_heads
self.dk = d_model // num_heads
self.Wq = nn.Linear(d_model, d_model) # Wx+b
self.Wk = nn.Linear(d_model, d_model)
self.Wv = nn.Linear(d_model, d_model)
self.Wo = nn.Linear(d_model, d_model)
self.drop = nn.Dropout(dropout)
def forward(self, q, k, v, mask: torch.Tensor | None = None):
B = q.size(0)
def split_heads(x):
# (B, L, D) -> (B, h, L, dk)
return x.view(B, -1, self.h, self.dk).transpose(1, 2)
Q = split_heads(self.Wq(q))
K = split_heads(self.Wk(k))
V = split_heads(self.Wv(v))
scores = Q @ K.transpose(-2, -1) / math.sqrt(self.dk) # (B, h, Lq, Lk)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
attn = torch.softmax(scores, dim=-1)
attn = self.drop(attn)
out = attn @ V # (B, h, Lq, dk)
out = out.transpose(1, 2).contiguous().view(B, -1, self.h * self.dk) # (B, Lq, D)
return self.Wo(out) # (B, Lq, D)
# ---- Position-wise FeedForward (兩層線性 Wx+b) ----
class FeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int = 2048, dropout: float = 0.1):
super().__init__()
self.lin1 = nn.Linear(d_model, d_ff)
self.lin2 = nn.Linear(d_ff, d_model)
self.drop = nn.Dropout(dropout)
def forward(self, x):
return self.lin2(self.drop(F.relu(self.lin1(x))))
# ---- Encoder/Decoder Layer ----
class EncoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ff = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.drop = nn.Dropout(dropout)
def forward(self, x, src_mask: torch.Tensor | None = None):
x = self.norm1(x + self.drop(self.self_attn(x, x, x, src_mask)))
x = self.norm2(x + self.drop(self.ff(x)))
return x
class DecoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ff = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.drop = nn.Dropout(dropout)
def forward(self, x, memory, tgt_mask: torch.Tensor | None, memory_mask: torch.Tensor | None):
x = self.norm1(x + self.drop(self.self_attn(x, x, x, tgt_mask)))
x = self.norm2(x + self.drop(self.cross_attn(x, memory, memory, memory_mask)))
x = self.norm3(x + self.drop(self.ff(x)))
return x
# ---- Stacks ----
class Encoder(nn.Module):
def __init__(self, vocab_size: int, d_model: int, N: int, num_heads: int, d_ff: int,
dropout: float = 0.1, pad_idx: int = 0):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model, padding_idx=pad_idx)
self.pos = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(N)])
self.drop = nn.Dropout(dropout)
self.pad_idx = pad_idx
def forward(self, src):
src_mask = make_pad_mask(src, self.pad_idx) # (B,1,1,Ls)
x = self.embed(src) * math.sqrt(self.embed.embedding_dim)
x = self.drop(self.pos(x))
for layer in self.layers:
x = layer(x, src_mask)
return x, src_mask
class Decoder(nn.Module):
def __init__(self, vocab_size: int, d_model: int, N: int, num_heads: int, d_ff: int,
dropout: float = 0.1, pad_idx: int = 0):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model, padding_idx=pad_idx)
self.pos = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(N)])
self.drop = nn.Dropout(dropout)
self.pad_idx = pad_idx
self.d_model = d_model
def forward(self, tgt, memory, memory_mask):
B, Lt = tgt.shape
pad = make_pad_mask(tgt, self.pad_idx) # (B,1,1,Lt)
causal = make_subsequent_mask(Lt, tgt.device) # (Lt,Lt)
tgt_mask = pad & causal.unsqueeze(0).unsqueeze(1) # (B,1,Lt,Lt)
x = self.embed(tgt) * math.sqrt(self.d_model)
x = self.drop(self.pos(x))
for layer in self.layers:
x = layer(x, memory, tgt_mask, memory_mask)
return x
# ---- Transformer ----
class Transformer(nn.Module):
def __init__(self, src_vocab: int, tgt_vocab: int, d_model: int = 512, N: int = 6,
num_heads: int = 8, d_ff: int = 2048, dropout: float = 0.1, pad_idx: int = 0):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, num_heads, d_ff, dropout, pad_idx)
self.decoder = Decoder(tgt_vocab, d_model, N, num_heads, d_ff, dropout, pad_idx)
self.generator = nn.Linear(d_model, tgt_vocab) # 最終 Wx+b
self.pad_idx = pad_idx
def forward(self, src, tgt):
memory, src_mask = self.encoder(src)
out = self.decoder(tgt, memory, src_mask)
logits = self.generator(out) # (B, Lt, Vt)
return logits
@torch.no_grad()
def greedy_decode(self, src, bos_idx: int, eos_idx: int, max_len: int = 64, device: str = "cpu"):
self.eval()
memory, src_mask = self.encoder(src.to(device))
B = src.size(0)
ys = torch.full((B, 1), bos_idx, dtype=torch.long, device=device)
for _ in range(max_len - 1):
dec = self.decoder(ys, memory, src_mask)
next_token = self.generator(dec[:, -1:, :]).argmax(-1) # (B,1)
ys = torch.cat([ys, next_token], dim=1)
if (next_token == eos_idx).all():
break
return ys
下一章我們要聚焦於 Decoder-only 架構的 GPT-2,與 Encoder-Decoder 不同 GPT-2 完全放棄 Encoder,只依靠多層 Decoder 與 Causal Mask 來進行生成。這樣的設計大幅簡化了結構並提升了可擴展性,但同時也增加了幻覺的風險。因此明天解析 GPT-2 的設計理念、它與 Encoder-Decoder 的差異,以及為何這種簡化的架構能成為現今大型語言模型的主流基礎。


 iThome鐵人賽
iThome鐵人賽